Advent of Code on the MEGA65
Advent of Code, the annual non-competitive puzzle event for computer programmers, has begun for 2022. Here are a few tips for anyone who might want to try this year’s AoC on the MEGA65.

Advent of Code is an Advent calendar of computer programming puzzles, which just means it has something every day for the first 25 days of December and all participants are doing it concurrently, and there’s some light secular Christmas theming. The puzzles can be solved in any programming language, and many programmers use it as an opportunity to sharpen their skills with a language that they know or to learn a new language. The puzzles are primarily intended for programming on modern computers, and typically involve acting on sets of data to calculate a single-value result.
Vintage computer enthusiasts sometimes attempt AoC on old computers as an excuse to learn vintage programming, or just to spend some time each day writing code in a cozy environment without Internet access. This poses additional AoC challenges. How do you get the input data set for today’s puzzle off of the AoC website and onto the vintage computer? How do you read and parse data files?
Below are some tips for attempting AoC puzzles on the MEGA65. You can use similar techniques for the Commodore 64 and Commodore 128 if you have a modern peripheral that emulates a disk drive, such as an Ultimate II+ cartridge or an SD2IEC (purchase) device.
I’m publishing this a few days into the month of December, so the event has already begun. You can always start AoC from the beginning, or even visit puzzles from previous years.
Copying data files to the MEGA65
While it’s fun to use the MEGA65’s built-in physical floppy drive for that vintage floppy disk feel, it is more convenient to use a microSD card for copying data between the MEGA65 and a PC (Windows, Mac, or Linux). A microSD card prepared on the MEGA65 has a FAT32 partition that can be used with a a PC with microSD card reader. See your User’s Guide or my MEGA65 Welcome Guide for instructions on how to prepare a microSD card.
Among other things, the microSD card can contain disk images of the D81 format, which represents disks compatible with Commodore 1581 drives. You can download D81 files that others have made, or you can create empty D81 files in the MEGA65’s Freeze menu.
There are tools for PCs that can create and manipulate D81 disk images, as well as other vintage disk image types. DirMaster is a popular desktop app for Windows with many features, including creating new images and dragging files between images and your PC. Command-line tools such as cbmconvert (download) or c1541 (included with VICE) also work, though they can be difficult to use.
My personal favorite is droiD64, a desktop app similar to DirMaster. It has fewer features, but I like it because it’s fast and works on Windows, macOS, or Linux. It requires a Java 11 runtime, such as OpenJDK or the Oracle Java runtime.
Setting up droiD64 on Mac or Linux
Download droiD64-0.5b-bin.zip (SourceForge link), then expand the archive to create the droid64-0.5b folder. To run droiD64 on macOS or Linux, you can use the droid64.sh script.
There’s a bit of a trick: as written, this script expects the droiD64 folder to be the current working directory so it can find the lib/ subfolder, which isn’t the case if you just double-click on the script from the file browser. One way to run it is to open a Terminal, cd droid64-0.5b (wherever you put the folder), then run ./droid64.sh.
I prefer to simply repair the droid64.sh script, like so:
#!/bin/sh
DROID64DIR=`dirname "$(readlink -f "$0")"`
CPATH=$DROID64DIR/lib/droid64-0.5b.jar:$DROID64DIR/lib/jaxb-impl-2.3.3.jar:$DROID64DIR/lib/jakarta.activation-1.2.2.jar:$DROID64DIR/lib/postgresql-42.2.18.jar:$DROID64DIR/lib/protobuf-java-3.11.4.jar:$DROID64DIR/lib/checker-qual-3.5.0.jar:$DROID64DIR/lib/jakarta.xml.bind-api-2.3.3.jar:$DROID64DIR/lib/mysql-connector-java-8.0.22.jar:$DROID64DIR/lib/jakarta.activation-api-1.2.2.jar
exec java -classpath $CPATH -Xmx1024m droid64.DroiD64 $*
Now you can double-click on the droid64.sh icon from Finder to run it, or run it from the command line regardless of the current working directory.
Windows users can try the droid64.bat script. I haven’t tested whether it needs a similar modification, and I don’t know what the Windows batch file equivalent of this is. You can always just paste the full path to the droid64-0.5b folder before each lib/ instance, after you can given the folder a permanent home.
Creating a D81 disk image
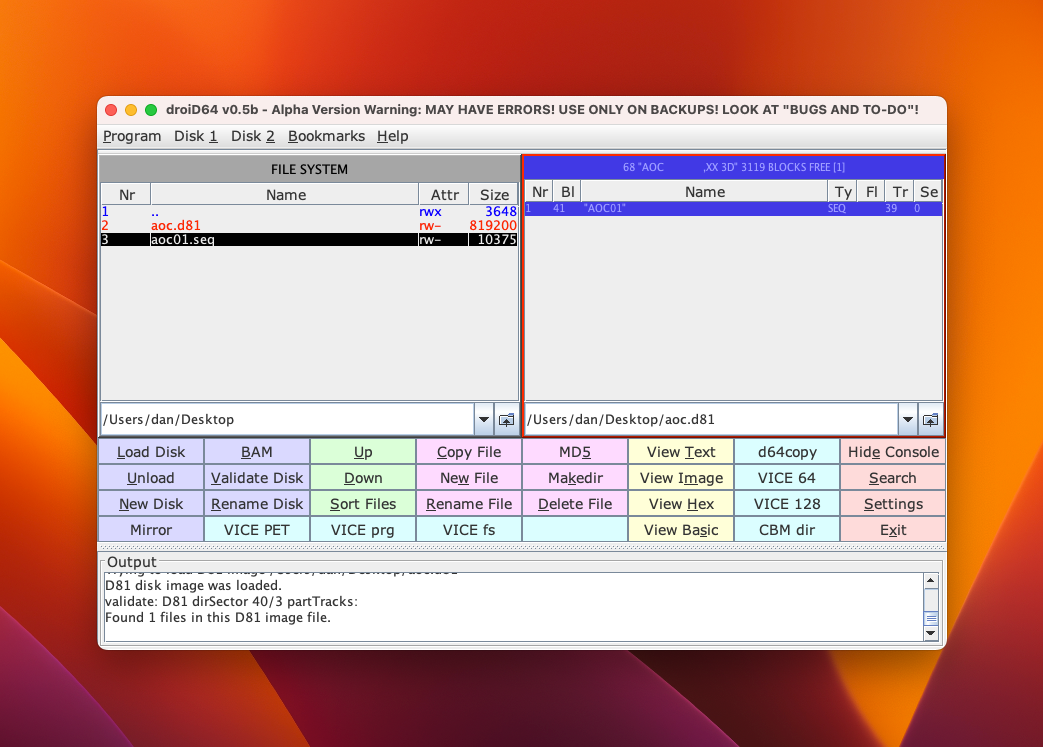
The droiD64 main window consists of two file browsers and a collection of action buttons. You can select a file browser by clicking on it; the selected browser has a red border. Some actions are performed on the currently selected directory or file. Other actions use both browsers.
Select the right-hand file browser, and browse to a location where you’d like to create a D81 disk image. Click the New Disk button. In the “New disk” dialog, select a type of D81. Provide a disk name (up to 16 letters and numbers) and a two-character ID (it doesn’t matter what the ID is). Click OK.
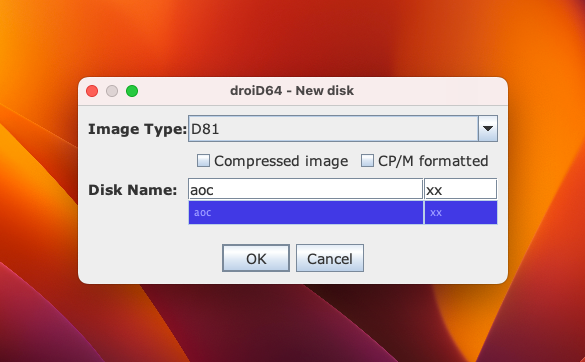
The “Save disk image” dialog opens already set to the selected folder, with a filename based on the disk name and a .d81 extension. Click Save.
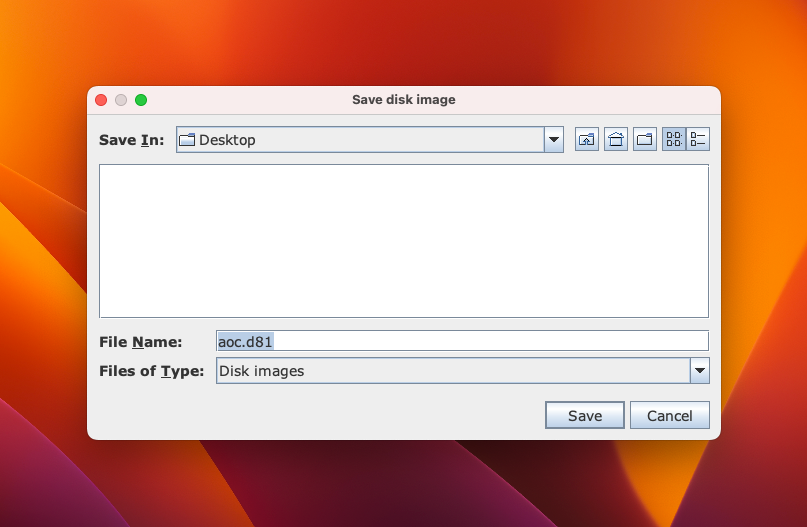
In the main window, the right-hand file browser is now inside the new D81 disk image. You can tell that it’s in the image because the title bar is now blue.
Transferring an AoC data file to the disk image
Download the AoC data file for the first December 1st puzzle from the website. Rename the file to use a .seq file extension and a short filename, such as: aoc01.seq
In the left-hand file browser, navigate to the data file. Select it, then click Copy File.
The disk image now has a SEQ file named AOC01.
Mounting the disk image on the MEGA65
Use your PC to copy the .d81 file to the microSD card. Eject the card, then re-insert it in your MEGA65.
If you know the name of the D81 file, the fastest way to mount it to drive unit 0 is with the MOUNT command:
MOUNT "AOC01.D81"
Alternatively, open the Freeze menu: hold Restore for a second then release. Press 0 to select drive unit 0, then use the cursor keys to select your disk image and press Return. Press F3 to return to BASIC.
Use the DIR command to confirm that your disk is mounted and your SEQ file is present.
Using the data file from BASIC
A SEQ file is a simple sequence of bytes. You can read such a file from BASIC using disk commands:
10 DOPEN#1,"AOC01"
20 GET#1,B$
30 IF ST THEN 60
40 PRINT B$;
50 GOTO 20
60 DCLOSE#1
This program reads each byte from the file one at a time, and tries to print it as if it were PETSCII. AoC input files will never be PETSCII, but we can at least use this to demonstrate that it is reading the file.
The first AoC 2022 Day 1 puzzle has an input file that consists of ASCII characters that represent a list of decimal numbers, separated by newline (ASCII value 10) bytes. We can modify this program to interpret the file and print it more cleanly:
5 V$=""
10 DOPEN#1,"AOC01"
20 GET#1,B$
30 IF ST THEN 110
40 IF ASC(B$)=10 THEN 70
50 V$=V$+B$
60 GOTO 20
70 V=VAL(V$)
80 PRINT V
90 V$=""
100 GOTO 20
110 DCLOSE#1
This reads each line one byte at a time, converting each byte to PETSCII and appending it to the V$ string variable. When it encounters a newline (10), it jumps to a routine to parse the contents of V$ as a decimal number using VAL() and store it in the V number variable (which is distinct from the V$ string variable). When it’s done with the value, it resets the V$ string, then returns to the read loop.
An actual solution to the Day 1 exercise needs to do something with the numeric value stored in V. This demonstration simply prints it on its own line. Notice that the data format for this puzzle includes meaningful blank lines, so a solution should test IF V$="" ... before calling DEC() to do something different with the blanks.
What does VAL() do when given a blank line? How would you find out? Is it safe to use the result of VAL() to detect a blank line, according to the problem description?
While you’re writing and testing your BASIC program, the program may fail before it gets to the DCLOSE#1 command. To stop the disk drive from making noise, enter DCLOSE#1 at the READY. prompt.
AoC in Mega Assembler
Would you rather use this opportunity to learn assembly language? A fun way to do this is with Mega Assembler by Thomas Gruber (grubi), an on-device assembly language coding environment.
Introducing Mega Assembler
Download the Mega Assembler disk image from Filehost, then copy it to your SD card. Mount the Mega Assembler disk image, then RUN "MEGA ASSEMBLER". Press the Help key to learn about its features.
The default assembly target address is $1800. This gives you 2048 bytes of code space before your program starts overwriting the assembler itself when assembling to memory, which is hopefully enough for AoC exercises. Of course, the starting address can be changed, and you can also assemble directly to disk. Mega Assembler v1.1 runs all the way from $2000 to $d59f, so there’s not much room in bank 0 for a long program that also keeps the assembler in memory.
Try one of the included examples:
- Press Mega-L to load an example, then type
TESTDRIVEand Return. - Press Mega-A to assemble.
- After assembly, press the R key to run it.
- The program performs its function (
TESTDRIVEperforms a mirror effect on the screen), then pauses. Press a key to exit back to the editor.
If we inspect the example code in the editor using the cursor keys, we notice two things:
- The
.RUN WAITdirective at the top causes the program to pause for a keypress when it is done when run from Mega Assembler..RUN CLEAR,WAITwill clear the screen before running, then wait for a keypress after. - The program ends with an
rtsinstruction. Mega Assembler invokes the program as a subroutine.
Loading AoC input data into memory
How do we access the data file from assembly language? We could try to write assembly code that calls kernel routines to access the SEQ file on disk, but this is a hassle for short exercises.
Here’s a simpler idea: before running Mega Assembler, load the input data into upper memory. Our assembly code can operate on memory instead of disk. This could be done with a BASIC program:
10 AD=$40000
20 DOPEN#1,"AOC01"
30 GET#1,B$
40 IF ST THEN 80
50 POKE AD,ASC(B$)
60 AD=AD+1
70 GOTO 30
80 DCLOSE#1
90 POKE AD,10
100 POKE AD+1,10
110 POKE AD+2,0
This loads the SEQ file into memory starting at address $40000. Save this BASIC program to the disk, and run it before loading Mega Assembler. If your program does not modify the input data, you can just leave it in memory while you work.
I added two values at the end of the dataset: a 10, a 10, and a 0 (lines 90-110). We might be able to do without these if we hard-code (or store) the data length in memory somewhere, and write our assembly program carefully enough not to go past that boundary and handle the edge case of the final value having nothing after it. By adding these values, I ensure that the last line with a value ends in a newline, there’s a blank line at the end to mark the end of the final list, and there’s a special character (a null) that doesn’t appear anywhere else in the data set that the program can use to identify the end of the data. I discovered that I needed this by inspecting the memory after run this BASIC program using the MONITOR.
With the data in upper memory, we can now load and run Mega Assembler and start coding.
Using upper memory
Mega Assembler is a BASIC program, and we want our program to be able to return to Mega Assembler when it finishes. This means we have to be careful not to write an assembly program that clobbers memory resources used by BASIC and Mega Assembler.
The first 64Kb of memory (bank 0, $00000-$0FFFF) is used by BASIC, our assembled program, Mega Assembler’s BASIC code, kernel ROM. The second 64Kb (bank 1) is used for BASIC disk operations ($10000-$11FFF), Mega Assembler’s working space ($12000-...), and BASIC working space. Banks 2 and 3 are ROM locations; a program can unlock these and overwrite them, but we need them to preserve BASIC.
Banks 4 and 5 are used by the BASIC hi-res graphics system, but we’re not using that for our assembly program, so we can use it for our data. I can imagine using BASIC hi-res graphics with a future AoC puzzle (or just to visualize something interesting), but I’d only use it from a BASIC program, and would try to take advantage of loading data directly from disk in that case instead of storing the entire dataset in memory.
The original 6502 CPU only knows how to access 64Kb of memory, from $0000-$FFFF. Successors to the 6502, including the MEGA65’s 45GS02, added backwards compatible ways to select upper banks. For our purposes, the best way to read our data from bank 4 is base page indexing: store a 32-bit address across four bytes in the base page, then refer to the base page address using a special type of instruction. For example, if we store 00 80 01 00 at addresses $fc-$ff on the base page, these instructions will load the byte stored at $00018000 into the accumulator:
ldz #0
lda [$fc],z
The lda [...],z instruction finds the 32-bit address on the base page, adds the Z register to it, then loads a byte from that address.
The default base page is $00xx, similar to the “zero page” on the Commodore 64. We can’t use this page without interfering with BASIC. Instead, we can tell the 45GS02 to use a different page of lower memory as the base page. The B register identifies this page, and we can set it by loading a value into the accumulator then calling the tab instruction. Base page $16xx is unused by BASIC, so:
; set the base page to $1600-16ff
lda #$16
tab
; ... our program goes here...
; reset the base page to $0000-00ff
lda #$00
tab
rts
Here’s an example that copies the first line of the input data to screen memory (assuming the first line is valid and fewer than 255 characters). It uses the 16-bit version of base page indexing to access the screen memory (sta (...),z), and increments the Z register to traverse the bytes.
.run clear,wait
; set the base page to $1600-16ff
lda #$16
tab
; store 32-bit address $00040000 at $1600
; store 16-bit address $0800 at $1604
lda #$00
sta $1600 ; 00 -- -- -- : -- --
sta $1601 ; 00 00 -- -- : -- --
sta $1603 ; 00 00 -- 00 : -- --
sta $1604 ; 00 00 -- 00 : 00 --
lda #$04
sta $1602 ; 00 00 04 00 : 00 --
lda #$08
sta $1605 ; 00 00 04 00 : 00 08
; copy the first line of input data to the upper left corner of the screen
ldz #0
loop
lda [$00],z ; read from the 32-bit address stored at $1600, offset by z
cmp #10 ; check for a newline (ASCII 10)
beq done
sta ($04),z ; store to the 16-bit address stored at $1604, offset by z
inz
bra loop
done
; reset the base page to $0000-00ff
lda #$00
tab
; return to mega assembler
rts
As written, this loop uses the Z register to offset the addresses stored on the base page. The Z register is 8 bits and can only go from 0 to 255.
- What would this code do if the first line of input data were longer than 255 bytes?
- How can we improve the loop to support copying a longer line? Hint: The Z register is an offset of the addresses stored in the base page. The
incinstruction can increment the value at a memory location. - If it’s safe to assume that all lines are shorter than 255 bytes, how would you write a routine that processes one line at a time?
AoC with a cross assembler
On-device coding is fun, but I enjoy the security of keeping my code on a modern PC, so I can use a modern text editor and revision control. We previously discussed how to do cross-assembly on a PC for the MEGA65 using the ACME assembler. What’s the best way to do AoC puzzles with ACME?
One idea, and probably the best one, is to attach the input file to the program itself. The program and the input file are stored together in the PRG file, and loaded as a contiguous block into memory when the program is loaded. In ACME, you do this with the !binary directive. An assembly program that starts with a BASIC header at $2001 can run all the way to $F6FF, almost 54 Kb.
Here’s the same program as above, this time using regular 16-bit base page indexing to load the data from the address determined by the assembler.
!cpu m65
!to "aoc01-asm.prg", cbm
* = $2001
!8 $12,$20,$0a,$00,$fe,$02,$20,$30,$3a,$9e,$20
!pet "$2014"
!8 $00,$00,$00
lda #$16
tab
; store the 16-bit address of the "data" label at $1600
lda #<data
sta $1600
lda #>data
sta $1601
; store the 16-bit address $0800 at $1602
lda #$00
sta $1602
lda #$08
sta $1603
; copy the first line of input data to the upper left corner of the screen
ldz #0
loop:
lda ($00),z ; read from the 16-bit address stored at $1600, offset by z
cmp #10 ; check for a newline (ASCII 10)
beq done
sta ($02),z ; store to the 16-bit address stored at $1604, offset by z
inz
bra loop
done:
; reset the base page to $0000-00ff
lda #$00
tab
; return to mega assembler
rts
data:
!binary "input.txt"
!byte 10,10,0
I have a USB serial interface and the latest version of the m65 tool that can auto-detect the serial port. I can cross-assemble this example and run it on my MEGA65 in a fraction of a second using these commands:
acme aoc01.asm
m65 -r aco01-asm.prg
Because we’re doing cross-assembly, we don’t need to be sensitive about BASIC’s needs. The assembly program can just print the result to the screen and enter an infinite loop, without ever exiting back to BASIC. You could even just leave the answer somewhere in memory then read it using the Matrix Mode debugger.
Next steps
For the first Day 1 exercise, we need to parse ASCII digits into numeric values and keep running totals larger than a 16-bit number. That’s easy in BASIC. In assembly language, we either need to write those routines ourselves, or locate existing kernel routines to do that for us. Future puzzles may require multiplication or division of numbers, or handling of fractions, and these are not built-in assembly language instructions. If these routines get long or complicated, it’s probably worth cross-assembling instead of using Mega Assembler so it’d be easier to reuse those routines in future puzzles.
Cross-assembly with the data attached to the PRG is as far as I would take this for AoC puzzles. For fun, I tried a version where the assembly program and data file were separate files, and a third BASIC loader copied the file to memory and loaded and ran the assembly code. This required cross-dev tooling to build the D81 disk image file, send it to the MEGA65 via mega65_ftp, and run it with m65 typing commands. It’s feasible, and it’s a potentially useful technique for large projects, but it’s slower than sending a single PRG over serial.
Coding or cross-dev testing with the Xemu emulator might be a reasonable trade-off for making it easy and fun to do AoC puzzles with MEGA65 tech.
Best of luck with AoC!